


SolidityBench by IQ foi lançado como o primeiro placar para avaliar LLMs na geração de código Solidity. Disponível em Abraçando o rostoapresenta dois benchmarks inovadores, NaïveJudge e HumanEval for Solidity, projetados para avaliar e classificar a proficiência de modelos de IA na geração de códigos de contratos inteligentes.
Desenvolvido por QI CérebroDAO como parte de seu próximo conjunto IQ Code, o SolidityBench serve para refinar seus próprios LLMs EVMind e compará-los com modelos generalistas e criados pela comunidade. O IQ Code visa oferecer modelos de IA adaptados para gerar e auditar códigos de contratos inteligentes, atendendo à crescente necessidade de aplicações blockchain seguras e eficientes.
Como o QI disse CriptoSlateo NaïveJudge oferece uma abordagem inovadora ao encarregar os LLMs de implementar contratos inteligentes com base em especificações detalhadas derivadas de contratos OpenZeppelin auditados. Esses contratos fornecem um padrão ouro de correção e eficiência. O código gerado é avaliado em relação a uma implementação de referência usando critérios como integridade funcional, adesão às melhores práticas e padrões de segurança do Solidity e eficiência de otimização.
O processo de avaliação aproveita LLMs avançadosincluindo diferentes versões do GPT-4 e Claude 3.5 Sonnet da OpenAI como revisores de código imparciais. Eles avaliam o código com base em critérios rigorosos, incluindo a implementação de todas as funcionalidades principais, tratamento de casos extremos, gerenciamento de erros, uso adequado de sintaxe e estrutura geral e capacidade de manutenção do código.
Considerações de otimização como eficiência de gás e gerenciamento de armazenamento também são avaliadas. As pontuações variam de 0 a 100, fornecendo uma avaliação abrangente de funcionalidade, segurança e eficiência, refletindo as complexidades do desenvolvimento profissional de contratos inteligentes.
Quais modelos de IA são melhores para o desenvolvimento de contratos inteligentes com solidez?
Os resultados do benchmarking mostraram que o modelo GPT-4o da OpenAI alcançou a pontuação geral mais alta de 80,05, com uma pontuação NaïveJudge de 72,18 e taxas de aprovação HumanEval for Solidity de 80% em pass@1 e 92% em pass@3.
Curiosamente, modelos de raciocínio mais recentes, como Pré-visualização o1 do OpenAI e o1-mini foram derrotados e ocuparam o primeiro lugar, marcando 77,61 e 75,08, respectivamente. Modelos da Anthropic e XAI, incluindo Claude 3.5 Sonnet e grok-2, demonstraram desempenho competitivo com pontuações gerais girando em torno de 74. Llama-3.1-Nemotron-70B da Nvidia teve a pontuação mais baixa entre os 10 primeiros, 52,54.
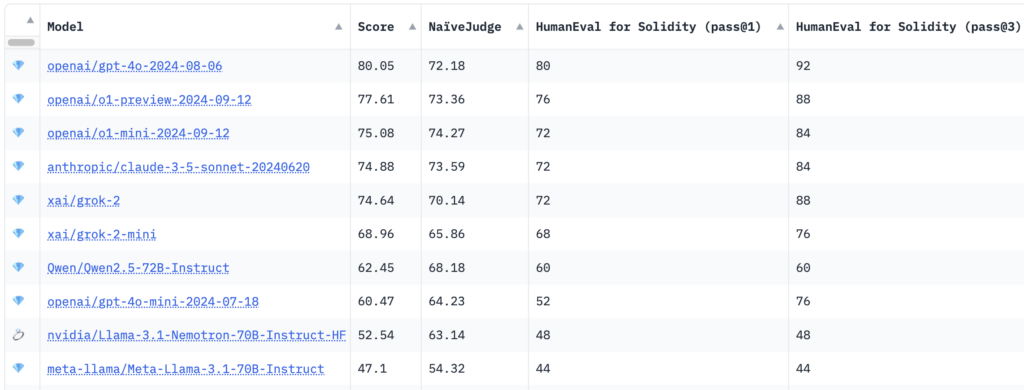
De acordo com o IQ, HumanEval for Solidity adapta o benchmark HumanEval original da OpenAI de Python para Solidity, abrangendo 25 tarefas de dificuldade variada. Cada tarefa inclui testes correspondentes compatíveis com Hardhat, um ambiente de desenvolvimento popular do Ethereum, facilitando a compilação e teste precisos do código gerado. As métricas de avaliação, pass@1 e pass@3, medem o sucesso do modelo nas tentativas iniciais e em múltiplas tentativas, oferecendo insights sobre precisão e capacidade de resolução de problemas.
Objetivos da utilização de modelos de IA no desenvolvimento de contratos inteligentes
Ao introduzir esses benchmarks, o SolidityBench busca avançar no desenvolvimento de contratos inteligentes assistidos por IA. Ele incentiva a criação de modelos de IA mais sofisticados e confiáveis, ao mesmo tempo que fornece aos desenvolvedores e pesquisadores informações valiosas sobre as capacidades e limitações atuais da IA no desenvolvimento do Solidity.
O kit de ferramentas de benchmarking visa avançar os LLMs EVMind do IQ Code e também estabelecer novos padrões para o desenvolvimento de contratos inteligentes assistidos por IA em todo o ecossistema blockchain. A iniciativa espera atender a uma necessidade crítica da indústria, onde a demanda por seguro e contratos inteligentes eficientes continuam a crescer.
Desenvolvedores, pesquisadores e entusiastas de IA estão convidados a explorar e contribuir com o SolidityBench, que visa impulsionar o refinamento contínuo de modelos de IA, promover melhores práticas e desenvolver aplicações descentralizadas.
Visite o SolidityBench tabela de classificação no Hugging Face para saber mais e começar a avaliar modelos de geração de Solidity.









